УДК 519.6:519.725:681.3
АЛГЕБРАИЧЕСКИЙ ПОДХОД К
ОБЪЕКТНО-ОРИЕНТИРОВАННЫМ БАЗАМ ДАННЫХ
Ó 2006 г. Емельченков Е. П., Мунерман В. И.
Рассмотрены методы математического
моделирования процессов проектирования информационных систем. Предложены
конструкции функциональных комплексов данных и абстрактных алгебраических машин, которые обеспечивают
языковое единство и оптимизацию на всех этапах разработки.
1. Введение
В [1] утверждается, что разработка любой системы
обработки информации представляет собой последовательность действий, каждому из
которых соответствует описание на некотором языке. Несогласованность этих
описаний, приводит к огромным непроизводительным затратам и существенно
тормозит развитие технологии разработки программного обеспечения информационных
систем (ИС). Каждое такое описание требует задания абстракций для объектов предметных
областей, их специфических свойств (атрибутов) и отношений между ними. При
этом, после определения новых абстракций, необходимо найти их место в контексте
уже существующих классов и объектов. Не стоит пытаться делать это строго сверху
вниз или снизу вверх. В [2] утверждается,
что "нет особой необходимости строить иерархию классов, начиная с самого
верхнего класса, и потом дополнять ее подклассами. Чаще вы создаете несколько
независимых иерархий, осознаете их общие черты и выделяете один или несколько
суперклассов. Требуется несколько проходов вверх и вниз по иерархии, чтобы
создать программный проект". Это наблюдение, основанное на опыте и подтверждающее
тот факт, что проектирование – это процесс последовательных приближений, и
именно в нем проявляется искусство проектировщика и программиста. Сходное
наблюдение встречается в [3]: "Наиболее частые реорганизации в иерархии
классов – это сведение совпадающих частей двух классов в один и разделение
класса на два новых". Интересно, что впервые подобный подход к проблеме
проектирования ИС был сделан на заре вычислительной техники и программирования
[4].
В [5, 6] была предложена
методика проектирования так называемых функциональных моделей данных.
Несущественное изменение этой методики позволяет проектировать модели данных со
сложной структурой, в том числе и объектно-ориентированные модели. В [1, 7]
были рассмотрены особые виды объектов, задаваемых в языках программирования и обеспечивающих
естественную связь упомянутых моделей данных со сложной структурой и современных
технологий программирования. Дальнейшее изложение посвящено объединению этих
двух подходов и их совместному развитию в общую теорию и технологию
проектирования информационных систем.
Предлагаемые в статье
решения позволят ответить на актуальные вопросы, сформулированные в [8], поскольку:
-
предоставляет отчетливую спецификацию объектно-ориентированных баз данных;
-
является, по сути, теоретическим
базисом для создания единого представления о моделях данных, так как использует традиционный
для математики алгебраический подход.
- предложенный подход
позволит проектировать базы данных,
которые могут справляться с очень сложными данными, которые способны
развиваться и обеспечивают высокую производительность, требуемую интерактивным
системам.
2.
Функциональные комплексы данных
При проектировании
информационной системы (ИС), предназначенной для решения задач в некоторой
предметной области, разработчик выделяет в ней объекты, представляющие интерес
для пользователя этой системы.
Каждый объект предметной
области однозначно идентифицируется в ИС с помощью специальной функции Id (идентификатор объекта). По сути
значения функции Id служат
уникальными именами объектов предметной области. Заметим, однако, что
пользователям ИС эти имена, как правило, не сообщаются. Они предназначены лишь
для представления объектов в информационной системе.
Примером функции Id на некотором предприятии может
служить код изделия (узла, детали).
В процессе проектирования
информационной системы с каждым конкретным объектом x предметной области
связывается определенный набор одноместных функций ![]() – атрибутов
(свойств), характеризующих объект x.
При отображении в информационной системе того или иного атрибута f объекта разработчик указывает имя
атрибута и описывает тип значений f.
Кроме имени f атрибута в
информационной системе для каждого конкретного объекта x хранится значение f(x) этого атрибута.
– атрибутов
(свойств), характеризующих объект x.
При отображении в информационной системе того или иного атрибута f объекта разработчик указывает имя
атрибута и описывает тип значений f.
Кроме имени f атрибута в
информационной системе для каждого конкретного объекта x хранится значение f(x) этого атрибута.
Таким образом, для каждого
атрибута объекта предметной области в информационной системе имеется не менее
двух записей: запись
описания (метаданные) и запись значения (данные).
Примерами атрибутов
объектов являются такие характеристики как: Цвет,
Вес, Дата изготовления, Возраст, Пол, Фамилия, Внешний
вид, Голос.
Описание упомянутых
атрибутов в информационной системе может оформляться различными способами.
Пример 1. Описание атрибута Цвет:
Dom(Цвет) = {красный, оранжевый, желтый, зеленый, голубой, синий, фиолетовый}.
Определенный таким образом
атрибут Цвет может принимать одно из
семи перечисленных в фигурных скобках значений. Если для некоторого объекта
значение атрибута Цвет есть "желтый", то в информационной системе этот факт может
отражаться в виде кортежа
(Цвет, желтый), первой компонентой
которого служит имя атрибута, а второй – его значение, или в виде таблицы
|
Цвет |
|
желтый |
Пример 2. Описание атрибута Вес: Dom(Вес) = Real.
Ограничения: Вес
![]() 0.
0.
В данном примере в качестве
домена атрибута Вес выбран стандартный тип данных
Real (встроенный или определяемый
системой скалярный тип). Это означает, что над значениями атрибута Вес можно выполнять все операции, которые определены
для типа Real, то есть операции + ,
- , ´, : и предикаты ![]() . Кроме того, для атрибута Вес
указано ограничение – его значения не могут быть отрицательными.
. Кроме того, для атрибута Вес
указано ограничение – его значения не могут быть отрицательными.
Пример 3. Описание атрибута Внешний
вид:
|
Имя атрибута |
Тип атрибута |
|
Внешний вид |
Фотография
в формате
JPEG |
Операции над значениями атрибута:
Контрастность(имя файла, t),
Яркость(имя
файла, t),
Размер(имя файла,
t),
где ![]() - параметр, позволяющий
увеличить (+) или уменьшить (-) соответственно контрастность, яркость
или размер фотографии с именем имя
файла.
- параметр, позволяющий
увеличить (+) или уменьшить (-) соответственно контрастность, яркость
или размер фотографии с именем имя
файла.
Значениями атрибута Внешний вид являются файлы с расширением jpg, в которых хранятся фотографии
объектов из предметной области.
Указывая формат (jpg) графического файла, в котором
хранится атрибут Внешний
вид,
разработчик информационной системы отмечает, что значения данного атрибута могут
быть обработаны, но не средствами информационной системы, а с помощью соответствующего
графического редактора, вообще говоря, внешнего по отношению к информационной
системе. Для значений атрибута Внешний
вид в
информационной системе обеспечиваются лишь указанные в описании атрибута
операции контрастность, яркость, размер.
Таким образом, для
информационной системы атрибут Внешний
вид является
скалярным типом данных с набором (из трех определенных разработчиком) скалярных
операций.
Пример 4. Описание атрибута Голос:
|
Имя атрибута |
Тип атрибута |
|
Голос |
Файл с записью голоса |
Операции над значениями атрибута:
Громче(имя файла),
Тише(имя файла),
позволяющие регулировать громкость звучания файла с
именем имя файла.
В данном примере
разработчик не определяет, в каком формате должны храниться значения атрибута Голос. Единственным требование к этому типу данных
является наличие двух унарных скалярных алгебраических операций Громче: Голос à Голос
и Тише: Голос à Голос.
Таким образом, определяемый
в примере тип Голос представляет собой алгебраическую
систему с двумя унарными операциями
V = <Голос; Громче, Тише>.
При необходимости
разработчик мог бы, например, дополнить систему двухместным предикатом Похожие(имя
файла, имя файла), принимающем
значение true, если в указанны в
качестве операндов файлах хранятся похожие голоса.
Приведенные примеры
показывают, что каждое значение атрибута объекта принадлежит некоторому носителю
определенной алгебраической системы, удовлетворяющей заданным требованиям
(ограничениям, аксиомам). Другими словами, каждый атрибут (тип) ассоциируется с
определенной аксиоматической теорией.
Кроме одноместных функций
при проектировании информационной системы разработчик определяет многоместные
функции, сопоставляющие нескольким значениям атрибутов объектов предметной области
определенные значения фиксированного типа. При описании таких функций в
информационной системе указываются имя функции, имена аргументов функции и их типы,
тип значений функции.
Пример 5. Описание трехместной функции данных Жильцы:
Жильцы: Улица, Дом, Квартира à Список
жильцов.
В этом описании предполагается, что типы данных Улица, Дом, Квартира, Список
жильцов
определены как char(25), byte, byte и set of char(20)
(символьный, числовые и множественный) соответственно. В отличие от остальных атрибутов
значением атрибута Список
жильцов
является сложный тип данных – множество.
Конкретные значения функции
Жильцы в информационной системе могут храниться как запись (кортеж)
((Улица, Варяжская),
(Дом, 62), (Квартира, 15),
(Список жильцов, {Иванов И.И., Иванов В.И.,
Сидорова Т.А.}))
или в виде таблицы:
|
Улица |
Дом |
Квартира |
Список_жильцов |
|
Варяжская |
62 |
15 |
{Иванов
И.И., Иванов В.И., Сидорова Т.А.} |
При проектировании
информационной системы допускается использовать различные конструкторы сложных
типов, такие как конструктор кортежей (Tuple),
конструктор множеств (Set),
конструктор списков (List),
конструктор массивов (Array).
Множества необходимы, потому что они обеспечивают естественный способ
представления наборов объектов предметной области. Списки или массивы важны
потому, что они сохраняют порядок, который имеет место в предметной области, а
также потому, что они присутствуют во многих научных приложениях в виде матриц
или временных рядов.
Как и в случае одноместных
функций данных, многоместные функции данных ассоциируются с многоосновными алгебраическими
системами, удовлетворяющими некоторым перечисленным в описании функций
условиям, или, другими словами, с аксиоматическими теориями. При этом носители
таких аксиоматических теорий могут быть весьма сложно устроены.
Получаемые в результате
такого проектирования конструкции называются функциональными комплексами
данных или сокращенно ФКД.
В ФКД конструкторы типов
применимы к любым типам данных. Это соответствует требованию ортогональности,
выдвинутому в [9], что позволяет строить таблицы подобные приведенной на
рисунке 1, где в роли элементов кортежей (полей таблицы) могут выступать кортежи
и таблицы.
В реляционной же модели
конструкторы не ортогональны, потому что конструкция множества может быть
применена только к кортежам, а конструкция кортежа – только к атомарным
значениям. Частичным решением проблемы ортогональности может быть использование
реляционных моделей в не первой нормальной форме (non-first normal form или NFNF),
в которых конструкцией верхнего уровня всегда должно быть отношение [10].

Рис. 1. Модель данных
в не первой нормальной форме
В современном понимании
модель данных – это не результат, а инструмент моделирования, то есть совокупность
правил структурирования данных, допустимых операций над ними и видов
ограничений целостности, которым они должны удовлетворять.
Функциональный комплекс
данных есть модель данных именно в таком смысле. С другой стороны, ФКД является
математической моделью понятия "модель данных" и может быть
представлен алгебраической структурой
< D; R; A
>, где
D –
заданное множество (носитель структуры);
R -
конечный набор отношений, в которых находятся элементы множества (типовая
характеристика структуры);
A -
ограничительные условия, накладываемые на отношения (аксиомы структуры).
Таким образом, ФКД – это
аксиоматическая теория [11]. Следовательно, на основе ФКД может быть построен
формальный язык манипулирования данными для первичного описания предметной
области [12], и ФКД служит основой для дальнейшей формализации в рамках
современных технологий программирования, о чем пойдет речь в следующем разделе.
3.
Абстрактные алгебраические машины
Этот раздел посвящен
алгебраическому подходу к проектированию ФКД и операторов языка манипулирования
данными в современных языках программирования. Обращение к алгебраическим
моделям не случайно, так как они позволяют строить формализованные модели
процессов обработки данных и решать задачи оптимизации этих процессов. В основу
построения алгебраических моделей положены понятия универсальной алгебры и
универсальной алгебраической системы, известные определения которых приведены
ниже.
Пусть A – некоторое непустое
множество. Частично определенная функция ![]() , называется n-арной частичной операцией на A. Если функция всюду определена,
говорят просто об n-арной операции.
, называется n-арной частичной операцией на A. Если функция всюду определена,
говорят просто об n-арной операции.
Система ![]() , состоящая из основного множества A и определенной на нем совокупности частичных операций
, состоящая из основного множества A и определенной на нем совокупности частичных операций ![]() , называется частичной
универсальной алгеброй с сигнатурой W.
, называется частичной
универсальной алгеброй с сигнатурой W.
Универсальные алгебры UA и UB , в которых заданы соответственно сигнатуры W и W', называются однотипными, если можно установить такое
взаимно-однозначное соответствие между сигнатурами W и W', при котором любая операция
w Î W и соответствующая ей
операция w' Î W' будут n-арными с одним и тем же n.
Пусть даны две однотипные
универсальные алгебры ![]() и
и ![]() с основными множествами
A и B.
с основными множествами
A и B.
Отображение j: A ® B называется гомоморфным
отображением алгебры ![]() в алгебру
в алгебру ![]() , если для любых элементов
, если для любых элементов ![]() и произвольной n-арной операции FÎW выполняется соотношение
и произвольной n-арной операции FÎW выполняется соотношение
![]() , где
, где ![]() и
и ![]() .
.
Алгебры ![]() и
и ![]() называются гомоморфными.
называются гомоморфными.
Пусть ![]() – n-местный предикат,
– n-местный предикат, ![]() – сигнатура
предикатов. Система UA=< A; W; P> называется универсальной алгебраической системой.
– сигнатура
предикатов. Система UA=< A; W; P> называется универсальной алгебраической системой.
Пример 6. Для трех задач из различных предметных областей: Разузлование (управление производством),
Поиск кратчайшего пути в графе из
заданной точки до остальных и Определение
доступности заданного множества точек из фиксированной точки в графе
(традиционные задачи исследования операций) может быть построен единый функциональный
комплекс данных. В этом ФКД в роли носителя выступает множество ориентированных
нагруженных графов G,
подобных графу, приведенному на рисунке 2. Пусть T 1 – подмножество
G, состоящее из графов,
подобных графу, приведенному на рисунке 3. Для преобразования произвольного
графа в граф, принадлежащий T1,
задается операция d. Можно потребовать выполнения аксиомы a :
d – всюду
определенная функция.
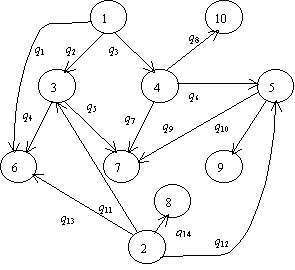
Рассмотренный ФКД является структурой типа < G; d ; a>. Ему соответствует универсальная алгебра UG=< G, {d }>. Операция d может быть реализована известным алгоритмом Дейкстры
[13], приведенном на листинге 1. Этот алгоритм не зависит от типа весов графа.
Однако в его реализациях используются операции над этими типами, определяемые
свойствами объектов предметной области.
Рис. 2. Граф не
принадлежащий T 1
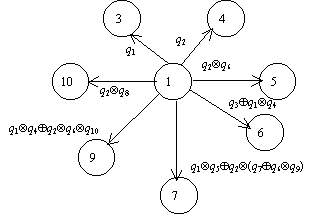
Рис. 3. Граф принадлежащий T 1
При
решении задачи Разузлование веса ребер – это
неотрицательные действительные числа с обычными операциями сложение и умножение. В задаче Поиск кратчайшего пути в графе из заданной
точки до остальных это также неотрицательные действительные числа с
операциями минимум и сложение
в качестве аддитивной и мультипликативной. И, наконец, в задаче Определение доступности заданного множества точек из фиксированной
точки в графе – это логические величины 0 и 1 и операции дизъюнкция и конъюнкция.
Листинг 1. Алгоритм Дейкстры
S:={1};
for i:=2 to n do
D[i]:=C[1,i];
for i:=1 to n-1 do
begin
выбрать из множества V \
S
вершину w и добавить ее к S; (*)
for каждой вершины v из множества V \
S do
D[v]:=
D[v] Å D[w] Ä C[w,v];
(**)
end;
Здесь
V – множество
вершин графа, S – множество пройденных вершин, C – двумерный массив весов,
а D – одномерный массив,
содержащий текущие "расстояния" от каждой вершины до источника. В
первой задаче "расстояние" – это количество узлов или деталей в изделии, во – второй длина кратчайшего пути,
а третьей – доступность вершины. Операции
в строках (*) и (**) также зависят от решаемой задачи.
Задача |
Строка |
||
|
* |
** |
||
|
Выбираемая вершина |
Аддитивная операция над весами Å |
Мультипликативная операция над весами Ä |
|
|
Разузлование |
Любая с ненулевым количеством |
Сложение |
Умножение |
|
Поиск кратчайшего пути в
графе из заданной точки до остальных |
Ближайшая (с минимальным значением длины) |
Минимум |
Сложение |
|
Определение доступности
заданного множества точек из фиксированной точки в графе |
Любая доступная |
Дизъюнкция |
Конъюнкция |
Случаи, когда можно
обойтись единственным основным множеством, встречаются нечасто, поскольку
объекты предметной области сложные системы, для описания которых используется
много разнотипных параметров. Для моделирования таких предметных областей
используются многоосновные алгебры.
Система UM =< M; W>, состоящая из семейства основных множеств M={Aa} (a = 1, 2, …) и сигнатуры W операций, определенных на
семействе M так, что каждая n-арная
операция из W является отображением
декартова произведения n
множеств из семейства M в множество из того же семейства ![]() называется многоосновной алгеброй.
называется многоосновной алгеброй.
Система UM=< M; W; P>, где P – сигнатура n-местных
предикатов ![]() , называется многоосновной алгебраической системой.
, называется многоосновной алгебраической системой.
Многоосновные алгебры и
алгебраические системы играют важную роль в программировании. Они служат
основой для создания пользовательских типов данных в современных языках
программирования, а ими являются некоторые встроенные в языки типы данных.
Пример 7. Пусть M=<
S, Z0;
W; P > – система, состоящая из
множества строк S и множества неотрицательных
целых чисел Z0. Сигнатура W состоит из операций:
![]()
![]()
![]()
![]()
В сигнатуру предикатов P можно включить предикаты π1
– "Cтрока s – пустая" и π2 – "Cтрока s1 предшествует строке s2". Таким образом,
строковый тип в языках программирования есть ни что иное, как двухосновная
универсальная алгебраическая система.
Очевидно, что системы
числовых матриц, нагруженных графов также можно рассматривать как многоосновные
алгебраические системы.
На многоосновных
алгебраических системах базируется современное теоретическое и практическое программирования.
Абстрактные типы данных (они же объекты или классы), сокращенно АТД, определяются как многоосновные алгебраические
системы.
Среди
множества произвольных абстрактных типов данных выделяется один специфический
вид. Эти АТД представляют собой
двухосновные алгебраические системы вида E=<S, T; W; P>.
Основу S назовем структурой, а T – типом.
Важная особенность этих АТД состоит в том, что суть
операций над элементами структуры S,
не изменяется при изменении сути операций над элементами типа T.
Так в примере 6 суть операции d не изменялась, оставаясь все тем же алгоритмом
Дейкстры при изменении строк (*) и (**).
Такие АТД будем называть абстрактными алгебраическими машинами
(ААМ).
При таком определении ААМ
основы сами должны быть универсальными алгебрами или алгебраическими системами.
Причем в качестве основы T
не используется конкретный тип данных. Задается только набор и характер его операций,
а также их свойства, определяемые требованиями заданных на S операций.
Для решения конкретных
задач строится наследник ААМ, в котором
в роли типа T выступает любой из встроенных в язык
программирования тип данных или спроектированный программистом АТД. Такой наследник ААМ называется ее моделью.
Пример 8. В примере рассматриваются абстрактная матричная машина и ее
модели, для решения задач Разузлование,
Поиск кратчайших путей между вершинами в
графе и Определение связности вершин
в графе. В отличие от примера 6, где эти задачи рассматривались как задачи
с одним источником, здесь они будут рассмотрены в общем случае. Их решение основано
на использовании алгоритма транзитивного замыкания матриц, элементами которых будут,
как и в примере 6:
- для Разузлования: неотрицательные действительные числа с обычными
операциями сложение и умножение;
- для Поиска кратчайших путей между вершинами в графе: неотрицательные действительные числа с аддитивной
операцией минимум и мультипликативной
операцией сложение;
- для Определения связности вершин в графе: {0,1} с операциями дизъюнкция и конъюнкция.
Абстрактная матричная
машина представлена на листинге 2. Для реализации операций над матрицами
необходимы переменные, заданные типами процедур (функций), реализующих операции
над элементами матриц в моделях. В операции сложения матриц используется только
процедура сложения элементов EAdd, а в операции умножения матриц используются операции обнуления элементов ENull и EMult для
вычисления элементов по формуле cik= cik Å aij Ä bjk. Переменные Ri, Rj
и Rk (регистры индексов матриц)
используются операциями над элементами для синхронизации вычислений в процессе
выполнения операций над матрицами и их элементами. Процедура Init
настраивает операции над элементами матриц. Процедуры MatAdd и MatMult реализуют
операции сложения и умножения матриц.
Листинг 2. Абстрактная матричная машина
type
{Типы
процедур обработки элементов матриц}
TNull = procedure
of object ; {Обнуление}
TAdd = procedure
of object ; {Сложение}
TMult = procedure
of object ; {Умножение}
{АТД – абстрактная матричная машина}
TAbstractMatrixMachine = class(TObject)
Ri, Rj,
Rk : word; {Регистры индексов}
{Указатели на процедуры, реализующие операции над элементами типа}
EAdd : TAdd;
EMult : TMult;
ENull :
TNull;
{Инициализация
операций над элементами типа}
procedure Init(_EAdd : TAdd; _EMult : TMult; _ENull : TNull);
{Операции
над абстрактными матрицами}
procedure MatAdd; {Сложение}
procedure MatMult; {Умножение}
end;
procedure
TAbstractMatrixMachine.Init(_EAdd : TAdd; _EMult : TMult; _ENull : TNull);
begin
ENull := _ENull;
EAdd := _EAdd;
EMult := _EMult;
end;
procedure
TAbstractMatrixMachine.MatAdd;
var
i,
j : word;
begin
for
i := 1 to N do
for
j := 1 to N do
begin
Ri := i; {Установка регистров индексов}
Rj := j;
EAdd;
end;
end;
procedure
TAbstractMatrixMachine.MatMult;
var
i, j,k
: word;
begin
for
i :=1 to N do
for
k :=1 to N do
begin
Ri := i; {Установка регистров индексов}
Rk := k;
ENull;
for
j :=1 to N do
begin
Rj :=
j;
EMult;
end;
end;
end;
Булевская модель матричной машины для решения
задачи Определение
связности вершин в графе представлена на листинге 3. Она начинается с объявления
булевской матрицы (*) как двумерного массива логических значений. АТД TBooleanMatrixMachine строится как наследник
АТД TAbstractMatrixMachine. Для вычислений
используются переменные RMA, RMB и RMC
(матрицы-регистры). Процедуры Zero, Add и Mult реализуют операции над
элементами. Процедура ConstructModel настраивает адреса операций над
элементами.
Листинг 3. Булевская модель матричной машины
TBMat=array[1..N, 1..N] of boolean; {Тип булевской матрицы} (*)
TBooleanMatrixMachine = class(TAbstractMatrixMachine)
RMA, RMB, RMC : TBMat; {Регистры матриц}
procedure Zero;
procedure
Add; {Сложение
элементов}
procedure
Mult;
{Умножение элементов}
procedure ConstructModel; {Инициализация модели}
end;
procedure
TBooleanMatrixMachine.Zero;
begin
RMC[Ri,Rk]
:= false; (**)
end;
procedure
TBooleanMatrixMachine.Add;
begin
RMC[Ri,Rj]
:= RMA[Ri,Rj] or
RMB[Ri,Rj]; (***)
end;
procedure
TBooleanMatrixMachine.Mult;
begin
RMC[Ri,Rk]
:= RMC[Ri,Rk] or
RMA[Ri,Rj] and RMB[Rj,Rk]; (****)
end;
procedure TBooleanMatrixMachine.ConstructModel;
begin
Init(Add,Mult,Zero); {Инициализация
операций над элементами}
end;
При реализации моделей, для
решения задач Разузлование и Поиска кратчайших путей между вершинами в
графе, тип матриц-регистров будет следующим: TRMat=array[1..N, 1..N] of real;, представляя собой двумерный массив действительных переменных.
Алгоритмы реализации операций над элементами будут следующими:
|
Оператор |
Разузлование |
|
(**) |
RMC[Ri,Rk]
:= 0; |
|
(***) |
RMC[Ri,Rj] := RMA[Ri,Rj] + RMB[Ri,Rj]; |
|
(****) |
RMC[Ri,Rk] := RMC[Ri,Rk] +
RMA[Ri,Rj] * RMB[Rj,Rk]; |
|
|
Поиск кратчайших путей |
|
(**) |
RMC[Ri,Rk] := infinity; {Константа infinity равна наибольшему значению в типе} |
|
(***) |
if RMA[Ri,Rj] < RMB[Ri,Rj] then RMC[Ri,Rj]
:= RMA[Ri,Rj] else RMC[Ri,Rj]
:= RMB[Ri,Rj]; |
|
(****) |
if RMC[Ri,Rk]> RMA[Ri,Rj] * RMB[Rj,Rk] then RMC[Ri,Rk]
:= RMA[Ri,Rj] * RMB[Rj,Rk]; |
Построенные таким образом модели абстрактной матричной
машины позволяют решать поставленные задачи.
4. Заключение
Рассмотренные
в статье методы позволяют решить одну из важнейших проблем проектирования информационных
систем – создание единого языка спецификаций, позволяющего на всех этапах
разработки использовать одинаковые понятия для описания данных и операций их
обработки. Функциональные комплексы данных и абстрактные алгебраические машины
дают решение этой проблемы, так как являются гомоморфными структурами. Поэтому
мы можем говорить о единстве моделей данных и операций на всех этапах проектирования.
В результате становится возможной оптимизация на всех
уровнях проектирования, так как при переходе на следующий уровень сохраняются
результаты оптимизации предыдущего уровня. Кроме того, абстрактные
алгебраические машины составляют основу для решения задач оптимизации
алгоритмов, реализующих процессы обработки данных. Оптимизация становится
возможной благодаря отделению операций структуры от операций над элементами
типа. При этом качество алгоритмов, реализующих операции структуры, не зависит
от качества алгоритмов, реализующих операции типа.
И, наконец, при необходимости использования
параллельных вычислительных систем, решение проектирование информационной
системы можно начинать с выбора структур, допускающих простое и эффективное
распараллеливание, а ФКД разрабатывать с учетом этих структур. Такой подход
существенно упрощает весьма актуальную сегодня проблему использования массовых
параллельных систем, основанных на многоядерных процессорах.
Литература
1.
Левин Н. А.,
Мунерман В. И. Алгебраический подход к оптимизации обработки информации. –
Системы и средства информатики. Спецвыпуск. Математические модели и методы
информатики, стохастические технологии и системы. Москва: ИПИ РАН 2005. – c.
279-294. ISBN: 5-902030-16-1.
2.
Halbert, D. and O'Brien, P. September 1988. Using
Types and Inheritance in Object-oriented Programming. IEEE Software vol.4(5),
p.75.
3.
Stroustrup, В. 1991. The C++ Programming Language, Second Edition. Reading, Massachusetts:
Addison-Wesley, p.377.
4. Канторович Л. В. Перспективы
крупноблочного подхода в прикладной математике, программировании и
вычислительной технике // Записки научных семинаров ЛОМИ, 1974,
т. 48, с. 5–11.
5. Емельченков Е. П., Малеин Ю. С. О
функциональном подходе в теории баз данных. //Деп. в ВИНИТИ № 6046-84, 1984. –
29 с.
6. Емельченков Е. П., Крюков П. П., Малеин Ю. С.
О математическом аппарате информационно логического обеспечения САПР ТП. //
Автоматика и телемеханика. М.: АН СССР, 1990, № 4. – с. 177-183.
7. Букачев Д. С., Мунерман В. И. О принципах
реализации виртуальных алгебраических машин. //Системы компьютерной математики
и их приложения: Материалы международной конференции. – Смоленск, СмолГУ, 2006.
– с. 55-56.
8. Аткинсон М., Бансилон Ф., ДеВитт Д., Диттрих
К., Майер Д., Здоник С. Манифест систем объектно-ориентированных баз данных. –
"Системы управления базами данных" //Издательство "Открытые
Системы"
9. Дейт К. Дж., Дарвен Х. Основы будущих систем
баз данных. Третий манифест. . – М.: Янус-К, 2004. – 656 с.
10. Yemelchenkov
Ye. P., Tsalenko M. Sh.
Functional dependencies in hierarchical Structures of Data. Lect. notes in
Compute Science. Berlin, 1991. V. 495. P. 258-275.
11. Бурбаки Н. Теория множеств. – М.: Мир, 1968.
12. Когаловский М. Р. Перспективные технологии
информационных систем. - М.: ДМК Пресс, 2003. – 288 с.
13. Емельченков Е. П., Левин Н. А. О
моделировании сложных предметных областей //Проблемы и методы информатики. II
Научная сессия ИПИ РАН: Тезисы докладов / под ред. И.А. Соколова. – М.: ИПИ
РАН, 2005. – с. 89-91.
14. Ахо А., Хопкрофт Дж., Ульман Дж. Структуры
данных и алгоритмы. – М.: Издательский дом «Вильямс», 2000. – 384 с.
The algebraic foundations of
the object-oriented data bases
Emelchenkov E. P., Munerman
V. I.
Methods of mathematical modeling of processes for designing the
information systems are considered. Designs of functional data complexes and
abstract algebraic machines which provide language unity and optimization at
all development cycles are offered.
Кафедра информатики
Смоленский государственный университет
Поступила в редакцию 16.11.2006.